背景
一个系统的数据质量不高通常是软件本身做的不够好,数据从源头就出现了问题。为了能够持续归总interface数据质量报告,来完善系统流程,我们就需要定量定性的分析源头数据。
现状及问题
首先,我们为了能够更好的support产品issue,上游系统的消息以及处理之后的回馈信息,都会被保存在关系数据库里,对于我们来说,可以简单分析处理后的回馈信息,按照消息类型,消息源系统来分类,解析message,抽取error code,最后归总报告。
流程很清晰,但是落实到代码,如果简单利用cursor一行行读出来处理的话,效率肯定极其低下,怎么办? 并行计算!可以利用MapReduce来处理。但是我们应该如何将保存在Oracle中Message导入Hadoop的HDFS中呢?
解决方案
Sqoop ! Sqoop 是一个开源框架,用来实现Hadoop和关系数据库之间的数据迁移,使用截图如下
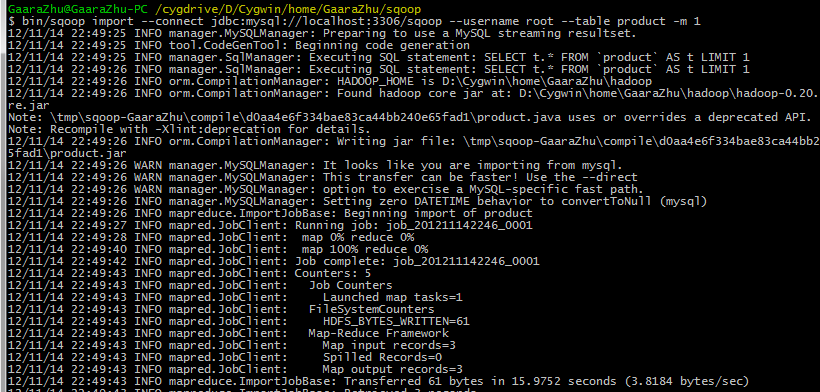
从执行数据迁移时的截图可以看出Sqoop本身也是基于MapReduce设计的,所以他支持并行导入/导出数据,更为给力的是,在导入条件里,你可以用SQL来进行数据过滤,只导入/导出你关心的行或者列。但是Sqoop在大数据量迁移的时候性能不是很好,尤其在Oracle和Hadoop之间,不过不用担心,我们可以使用开源插件来提升Sqoop数据迁移性能,比如Quest Connector。其实Oracle本身也有类似的插件,但是:
- 它只支持从Hadoop到Oracle的数据迁移
- 它不是免费的
在数据被正确导入到HDFS之后,我们就可以开始编写MapReduce函数了,首先在map函数里根据消息类型,case by case的进行text ->xml object的转换,然后截取反馈信息(error code),接着在reduce函数里面按照源系统进行分区,汇总,最后再利用Sqoop导入Oracle。
总结
定期的分析汇总已经结束,然后就需要持续follow了,就像每周的ART报告一样,需要定期查看最近的接口数据质量,来持续完成系统的改进和优化.