背景
前段时间看了篇文章,讲Youku网数据库架构的演变,如何从最开始的读写分离,再到垂直分区,最后到水平分片,一步一步慢慢成熟的。看完之后很有冲动抽出一个模型来把这几种技术都实现一下。说干就干,首先是读写分离。
实现方案
我使用的数据库是Mysql,主从数据复制用的是半同步机制(mysql版本必须 5.5以上),具体配置,可以参照这篇文章: http://blog.csdn.net/changerlove/article/details/6167255, 要注意Windows环境下,mysql配置文件为my.ini, linux下才是my.cnf。
然后主从复制有两类做法,一类就是在应用层去动态切换数据源,最简单的做法就是根据事务类型来做Route,另外一类就是利用所谓的“中间件”,在应用层和数据源之间通过分析SQL来Route,目前可选的“中间件有Mysql自带的Mysql Proxy还有阿里开发的Amoeba,后者据说比Mysql Proxy更稳定,使用也更简单,所以“中间件”做法里我选了第二种来尝试,待会儿会分析Amoeba的优劣,这儿先讲第一种做法,在应用层实现读写分离。
Spring+JPA应用层实现读写分离
实现
在例子中有两台Mysql Server,一台Master 负责写,一台Slave负责读,对应的JPA 配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0"
xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<!-- used to test R/W Splitting in MYSQL, can be routed by transaction
type(read only or not) -->
<persistence-unit name="MASTER_000" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/rws_db" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="" />
<property name="eclipselink.jdbc.read-connections.min"value="1" />
<property name="eclipselink.jdbc.write-connections.min"value="1" />
<property name="eclipselink.jdbc.batch-writing" value="JDBC" />
<property name="eclipselink.logging.level" value="FINE" />
<property name="eclipselink.logging.thread" value="false" />
<property name="eclipselink.logging.session" value="false" />
<property name="eclipselink.logging.exceptions" value="false" />
<property name="eclipselink.logging.timestamp" value="false" />
</properties>
</persistence-unit>
<persistence-unit name="SLAVE_000" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://146.222.51.163:3306/rws_db" />
<property name="javax.persistence.jdbc.user" value="zhuga3" />
<property name="javax.persistence.jdbc.password" value="Gmail123" />
<property name="eclipselink.jdbc.read-connections.min"value="1" />
<property name="eclipselink.jdbc.write-connections.min"value="1" />
<property name="eclipselink.jdbc.batch-writing" value="JDBC" />
<property name="eclipselink.logging.level" value="FINE" />
<property name="eclipselink.logging.thread" value="false" />
<property name="eclipselink.logging.session" value="false" />
<property name="eclipselink.logging.exceptions" value="false" />
<property name="eclipselink.logging.timestamp" value="false" />
</properties>
</persistence-unit>
</persistence>
然后系统的事务控制,这个是关键,因为在事务初始化的时候要根据事务属性(R/W)来初始化对应的EntityManager,并开启事务,简单起见,例子里使用JPA的Entity Transaction,而不是JTA。
实现第一步,我们得自定义transactionManager来控制事务的开关,回滚以及资源的初始化等等,直接看代码吧:
package util.transaction;
import javax.persistence.EntityManager;
import javax.persistence.EntityTransaction;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.TransactionException;
import org.springframework.transaction.support.AbstractPlatformTransactionManager;
import org.springframework.transaction.support.DefaultTransactionStatus;
public class RWSTransactionManager extends AbstractPlatformTransactionManager {
private static final long serialVersionUID = -1369860968344021154L;
@Override
protected Object doGetTransaction() throws TransactionException {
RWSJPATransactionObject rwsTransaction = new RWSJPATransactionObject();
EntityManager entityManager = EntityManagerHolder.getInstance()
.initializeResource(definition.isReadOnly());
EntityTransaction transaction = entityManager.getTransaction();
rwsTransaction.setTransaction(transaction);
return rwsTransaction;
}
@Override
protected void doBegin(Object txObject, TransactionDefinition definition)
throws TransactionException {
RWSJPATransactionObject rwsTransaction = (RWSJPATransactionObject) txObject;
if (!definition.isReadOnly()) {
rwsTransaction.getTransaction().begin();
}
}
@Override
protected void doCommit(DefaultTransactionStatus transactionStatus)
throws TransactionException {
if (transactionStatus.isReadOnly()) {
return;
}
RWSJPATransactionObject rwsTransaction = (RWSJPATransactionObject) transactionStatus
.getTransaction();
rwsTransaction.getTransaction().commit();
}
@Override
protected void doRollback(DefaultTransactionStatus transactionStatus)
throws TransactionException {
if (transactionStatus.isReadOnly()) {
return;
}
RWSJPATransactionObject rwsTransaction = (RWSJPATransactionObject) transactionStatus
.getTransaction();
rwsTransaction.getTransaction().rollback();
}
private class RWSJPATransactionObject {
private EntityTransaction transaction;
public EntityTransaction getTransaction() {
return transaction;
}
public void setTransaction(EntityTransaction transaction) {
this.transaction = transaction;
}
public RWSJPATransactionObject() {
super();
}
}
}
对应的 EntityManagerHolder 代码如下:
package util.transaction;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import org.apache.commons.lang.StringUtils;
public class EntityManagerHolder {
private Random random = new Random();
private String PERSISTENCE_UNIT_HEADER_MASTER = "MASTER_";
private String PERSISTENCE_UNIT_HEADER_SLAVE = "SLAVE_";
private final ThreadLocal<EntityManager> THREAD_LOCAL = new ThreadLocal<EntityManager>();
private final Map<String, EntityManagerFactory> RESOURCE = new HashMap<String, EntityManagerFactory>();
private static EntityManagerHolder emHolder;
private EntityManagerHolder() {
}
public static EntityManagerHolder getInstance() {
if (null == emHolder) {
emHolder = new EntityManagerHolder();
}
return emHolder;
}
EntityManager initializeResource(boolean isReadOnly) {
// get random persistence unit, dependents on master and slave
// quantities
// configured in persistence.xml
String puSuffix = "";
if (isReadOnly) {
puSuffix = StringUtils.leftPad(String.valueOf(random.nextInt(1)),
3, "0");
} else {
puSuffix = StringUtils.leftPad(String.valueOf(random.nextInt(1)),
3, "0");
}
String persistenceUnit = (isReadOnly ? PERSISTENCE_UNIT_HEADER_SLAVE
: PERSISTENCE_UNIT_HEADER_MASTER) + puSuffix;
return createEntityManager(persistenceUnit);
}
private EntityManager createEntityManager(String persistenceUnit) {
if (null == RESOURCE.get(persistenceUnit)) {
EntityManagerFactory entityManagerFactory = Persistence
.createEntityManagerFactory(persistenceUnit);
RESOURCE.put(persistenceUnit, entityManagerFactory);
}
EntityManager entityManager = THREAD_LOCAL.get();
if (null == entityManager || !entityManager.isOpen()) {
entityManager = RESOURCE.get(persistenceUnit).createEntityManager();
THREAD_LOCAL.set(entityManager);
}
return entityManager;
}
public EntityManager getEntityManager() {
EntityManager entityManager = THREAD_LOCAL.get();
if (null == entityManager) {
throw new IllegalArgumentException();
}
return entityManager;
}
public void closeEntityManager() {
EntityManager entityManager = THREAD_LOCAL.get();
THREAD_LOCAL.set(null);
if (null != entityManager)
entityManager.close();
}
}
可以看到,在getTransaction方法里我们简单new了一个自定义的Object,其实就是一个EntityTransaction holder,关键是在begin(..)方法里,首先会根据事务属性到EntityManagerHolder中进行资源初始化(主要是EMFactory和EM),在initializeResource 方法里面,简单的写了种路由算法,就是Java随机数,生成对应PersistenceUnit Name的后缀,最后根据这个name去生成对应的EMFactory和EM,并且set到Threadlocal的变量中去,之后在Dao层可以直接通过getEntityManager 方法来获取EntityManager.初始化结束之后,对应的事务直接使用EM里面的EntityTransaction来begin,commit和rollback。
事务管理器写好了,我们先看一下相关的Spring配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-2.5.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config />
<context:component-scan base-package="*" />
<bean id="transactionManager" class="util.transaction.RWSTransactionManager"/>
<tx:annotation-driven transaction-manager="transactionManager"/>
</beans>
最后需要在service上加上事务注解, 指明事务属性:
@Override
@Transactional(readOnly = false)
public void add(T object) {
getDao().push(object);
}
@Override
@Transactional(readOnly = true)
public List<T> findByExample(T object) {
return getDao().findByExample(object);
}
测试类:
package test;
import service.EmployeeService;
import test.mainTest.BaseMainTest;
import domain.Employee;
public class TestRWS extends BaseMainTest {
public static void main(String[] args) {
EmployeeService employeeService = (EmployeeService) ctx
.getBean("employeeService");
Employee employee = new Employee();
employee.setFirstName("Yinkan");
employee.setLastName("Zhu");
employeeService.add(employee);
// employeeService.findByExample(employee);
}
}
测试
当调用EmployeeService里面的Add方法时(事务属性为写事务),从Log里可以看到成功连接到Master Server,并且插入成功,从库里也同步过去了。

当调用EmployeeService里面的FindByExample方法的时候(事务属性为读事务),从Log里可以看到是从Slave Server读取数据:

到这里第一种方法,在应用层来实现读写分离已经结束了,可以看到,通过事务属性来进行数据源切换这种做法比较简单,但是从软件设计的角度来看,事务控制里面耦合了数据源切换的逻辑,下面一种做法,使用Amoeba直接在SQL level做Route,代码的耦合度大大降低,但是也带来了其他问题。
Amoeba中间件实现读写分离
实现
Amoeba的原理如下图所示,就是一层代理,对APP来说可见的只有一个DataSource,具体的Masters和Slaves可以在Amoeba里配置。
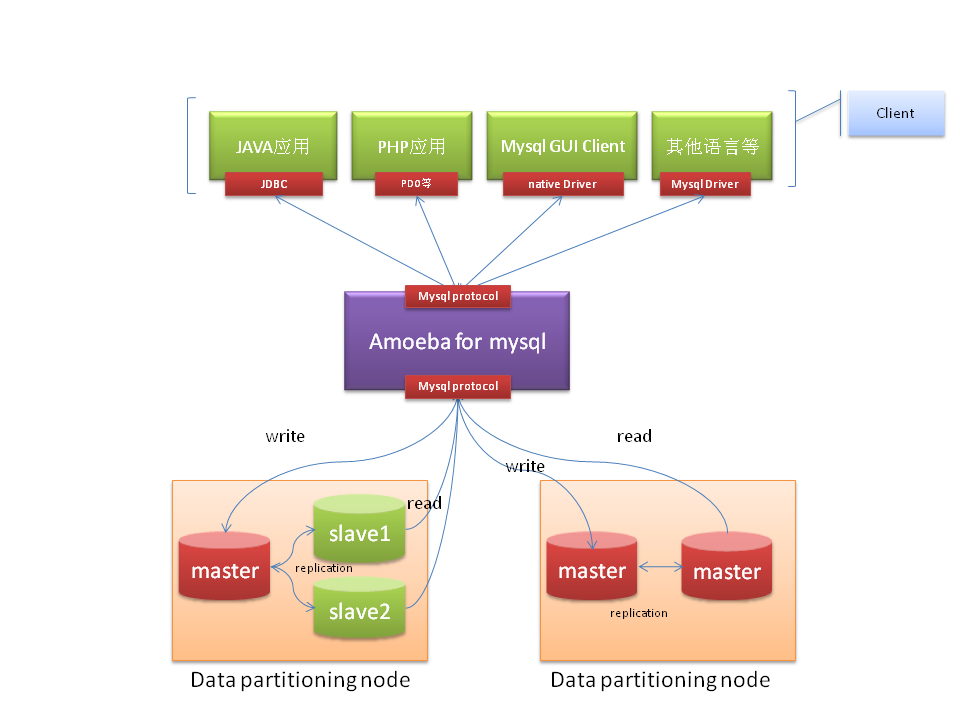 对应应用层JPA的配置如下:
对应应用层JPA的配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0"
xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="proxyPU" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<exclude-unlisted-classes>false</exclude-unlisted-classes>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:8066/rws_db" />
<property name="javax.persistence.jdbc.user" value="amoebaUser" />
<property name="javax.persistence.jdbc.password" value="123" />
<property name="eclipselink.jdbc.read-connections.min"value="1" />
<property name="eclipselink.jdbc.write-connections.min"value="1" />
<property name="eclipselink.jdbc.batch-writing" value="JDBC" />
<property name="eclipselink.logging.level" value="FINE" />
<property name="eclipselink.logging.thread" value="false" />
<property name="eclipselink.logging.session" value="false" />
<property name="eclipselink.logging.exceptions" value="false" />
<property name="eclipselink.logging.timestamp" value="false" />
</properties>
</persistence-unit>
</persistence>
该PersistenceUnit里面用到的Mysql相关信息,配置在Amoeba的amobe.xml文件里,是一个对外的proxy:
<!-- service class must implements com.meidusa.amoeba.service.Service -->
<service name="Amoeba for Mysql" class="com.meidusa.amoeba.net.ServerableConnectionManager">
<!-- port -->
<property name="port">8066</property>
<!-- bind ipAddress -->
<!--
<property name="ipAddress">127.0.0.1</property>
-->
<property name="manager">${clientConnectioneManager}</property>
<property name="connectionFactory">
<bean class="com.meidusa.amoeba.mysql.net.MysqlClientConnectionFactory">
<property name="sendBufferSize">128</property>
<property name="receiveBufferSize">64</property>
</bean>
</property>
<property name="authenticator">
<bean class="com.meidusa.amoeba.mysql.server.MysqlClientAuthenticator">
<property name="user">amoebaUser</property>
<property name="password">123</property>
<property name="filter">
<bean class="com.meidusa.amoeba.server.IPAccessController">
<property name="ipFile">${amoeba.home}/conf/access_list.conf</property>
</bean>
</property>
</bean>
</property>
</service>
然后是事务,事务的话可以直接使用Spring自带的JpaTransactionManager来管理,Entitymanager可以在Service层用annotation来注入,具体代码我就不贴了。
测试
一切准备好之后先启动Amoeba,我们来跑一下test, 首先是读,发现log如下:

可以看到Database version: 。。mysql-amoeba-proxy。。 说明连接正确,在看结果读数据也的正常的。
接下来就是测试写数据: 跑了一下,报错了:
Internal Exception: java.sql.SQLException: ResultSet is from UPDATE. No Data.
Error Code: 0
Call: SELECT LAST_INSERT_ID()
Check一下生成的SQL,发现insert之后跑了句SELECT LAST_INSERT_ID(), 因为我程序里Entity的主键是Mysql的自增主键,每次插入都会生成这句话用来返回当前ID,而这个ID是跟着Connection走的,也就是说如果该connection里面没有更新,就拿不到值,可是我们的insert和这句select难道不在一个Connection里面?对的,忘了我们用的是“SQL路由器”吗?insert语句开启主库connection,select则走的是从库的connection,所以查询当然是空了,而eclipselink查出resultSet之后直接.next()了,也没判断是否有值,于是就出现这个error code了,当然对于eclipselink,这种check只能说是nice to have的,正常情况下是不会出现这种情况的,connection在获取数据源的时候就已经有了,这里因为我们拿到的其实是个代理。
总结
考虑到Amoeba的实现原理,即"SQL路由",即使Mysql支持Oracle一样的主键生成策略,在这种情况下似乎也不能正常工作。所以得由应用层来生成主键,这又是Effort。。。
另外从Amoeba的文档里看到,他的另一个缺点是目前不支持事务,这个我的理解是跨connection的事务做不到原子性,特别是当规则配置多主情况下,事务无效。
这么看来Amoeba的使用场景确实有限,首先domain层最好不要使用JPA之类的ORM框架,纯JDBC开发更可靠;然后在数据库架构上,一主多从尽量原子化事务。
综合对比一下,应用层实现读写分离比较靠谱。
项目源码: https://github.com/GaaraZhu/RWSDemo