背景
在系统设计的时候,为了提高可用性,经常需要对用户行为进行分析,来持续完善系统。
一个典型的场景就是分析用户的查询条件,根据操作习惯和规律来精简用户输入,让查询变得更简单更高效。那么对于这种场景,我们应该如何实现?
解决方案
最简单的做法就是在每次查询的时候都把所用到的条件直接save到关系数据库,这种做法确实很简单,但是每次都需要做write操作,尤其对于操作密集型应用,我们不认为这是种很好的practise。或许你会说,可以做个内存队列,把信息缓存起来,然后batch write,这种做法性能确实比前一种更高效,而且对于统计用户使用信息这种场景,就算由于系统宕机导致的部分数据丢失,似乎也不会产生蝴蝶效应,但是我们总是想做得更好,于是,对于系统重启之类的可预知情况,我们可以利用RMI动态提交掉缓存中的数据,但是对于不可预知的情况,又该怎么办呢?或许我们可以找到其他更好的方法。
比如,直接把信息写到log里,然后安排一个schedual job来定期分析log,提取出信息再save到数据库,但是如果log很大很多,分析起来会不会很慢?查看了IPS PRD上的log,一天的log大概有几百M左右,而liner的数据量是logistic的10倍,log信息也会大出好几倍。而且通常为了trouble shooting,我们会保存一定期限的log,之后便会做house keeping,所以如果想在log被清掉之前做分析的话,仅仅是ARP项目,我们面对的就可能是几十个 N G的log文件,直接用JAVA分析?答案是可以的,用NIO,那还有其他办法吗?MapReduce!
MapReduce
MapReduce的分布式并行计算,说白了就是利用笨办法来暴力解决问题,对于统计用户查询条件这种场景,我们可以看到log片段如下:
877994 [[ACTIVE] ExecuteThread: '1' for queue: 'weblogic.kernel.Default (self-tuning)'] DEBUG com.easys.common.interceptor.HMILogDecorator 14 Sep 2012 11:01:23,023 - ARP_SEARCH_INVOICE-CTRLOFFICE-COLOFFICE-INVTYPE-BLNO
877994 [[ACTIVE] ExecuteThread: '1' for queue: 'weblogic.kernel.Default (self-tuning)'] DEBUG com.easys.common.interceptor.HMILogDecorator 14 Sep 2012 11:01:23,023 - ARP_SEARCH_INVOICE-CTRLOFFICE-COLOFFICE-INVNO-BLNO877994 [[ACTIVE] ExecuteThread: '1' for queue: 'weblogic.kernel.Default (self-tuning)'] DEBUG com.easys.common.interceptor.HMILogDecorator 14 Sep 2012 11:01:23,023 - ARP_SEARCH_PAYMENT-CTRLOFFICE-COLOFFICE-PMTNO
可以看到,我们关心的只是最后的一串字符“ARP_SEARCH_INVOICE-CTRLOFFICE-COLOFFICE-INVTYPE-BLNO“, 表示了功能名+所用条件,于是在MapReduce里面我们先定位到这段字符(实际log是不分行的,可以直接split),然后将其解析成 ([功能名, 条件] -> 1) 的key-value 对,之后交给Reduce函数做统计.
Map阶段:
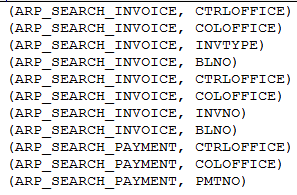
Reduce阶段:
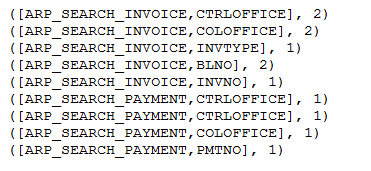
Reduce之后的结果我们可以直接导到关系数据库里,后续可以用SQL做分析出Report。 代码实现其实就是一个加强版的WordCount.
Map类
package com.easys.hmi.collectors;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SearchCriteriaMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String lineValue = value.toString();
String dataValue = lineValue.split("-", 3)[2].trim();
String functionName = dataValue.split("-", 2)[0].trim();
String criteriasValue= dataValue.split("-", 2)[1].trim();
String[] criterias = criteriasValue.split("-");
for (String criteria : criterias) {
StringBuffer sb = new StringBuffer();
sb.append(functionName).append("-").append(criteria);
context.write(new Text(sb.toString()), one);
}
}
}
Reduce类
package com.easys.hmi.collectors;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SearchCriteriaReducer extends
Reducer
{
private IntWritable totalCount = new IntWritable();
public void reduce(Text key, Iterable
values, Context context)
throws IOException, InterruptedException {
int total = 0;
for (IntWritable singleValue : values) {
total += singleValue.get();
}
totalCount.set(total);
context.write(key, totalCount);
}
}
总结
-
用户行为分析这种对数据实时性要求不高的功能,可以利用非结构化的方式来存储源数据,然后定期处理,生成结构化数据,存储到关系数据库,做后续分析。
-
MapReduce的使用与否取决于几个因素: 文件大小,文件数量,处理逻辑复杂度等等,对于简单的小文件处理,Java IO/NIO足够了,比如:上述的计算,在处理20个 50M的log文件的时候,伪分布式模式下使用Hadoop一共耗时90秒,而使用java IO,仅仅需要30秒就可以了。